
1. 예제 테이블 및 데이터
CREATE TABLE `employee` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(100) NULL DEFAULT NULL,
`salary` INT(11) NULL DEFAULT NULL
PRIMARY KEY (`id`)
)
CREATE TABLE `access_log` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`access_dt` DATETIME NULL DEFAULT '',
`emp_id` INT(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `fk_access_log_emp_id` FOREIGN KEY (`emp_id`) REFERENCES `employee` (`id`)
)
INSERT INTO `employee` (`id`, `name`, `salary`) VALUES (1, 'kim', 3000);
INSERT INTO `employee` (`id`, `name`, `salary`) VALUES (2, 'park', 2600);
INSERT INTO `employee` (`id`, `name`, `salary`) VALUES (3, 'lee', 7000);
INSERT INTO `employee` (`id`, `name`, `salary`) VALUES (4, 'go', 3400);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (1, '2021-03-28 16:30:55', 1);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (2, '2021-03-28 16:30:58', 1);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (3, '2021-03-28 16:31:01', 1);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (4, '2021-03-28 16:31:04', 2);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (5, '2021-03-28 16:31:05', 3);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (6, '2021-03-28 16:31:06', 3);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (7, '2021-03-28 16:31:08', 4);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (8, '2021-03-28 17:31:11', 4);
INSERT INTO `access_log` (`id`, `access_dt`, `emp_id`) VALUES (9, '2021-03-28 18:31:13', 1);
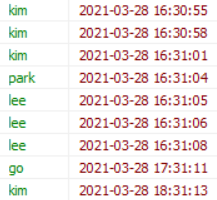
# 사원 접근 정보 조회
select emp.name, access.access_dt
from employee emp
join access_log access on (access.emp_id = emp.id)
2. distinct 란
distinct는 unique한 행을 조회 할 경우 사용합니다. 내부 동작 방식은 group by와 동일 하지만 중복 제거 후 정렬을 하지 않는다는 차이점이 있습니다. 그리고 distinct 명령어는 반드시 select 첫번째 컬럼 앞에 입력해야합니다.
1) 예제
2021-03-28 16:00:00 ~ 2021-03-28 16:59:59 에 접근한 사원 명을 중복없이 조회하고 싶다면 다음과 같은 쿼리를 입력하면 됩니다.
select distinct emp.id, emp.name
from employee emp
join access_log access on (access.emp_id = emp.id)
where access.access_dt between '2021-03-28 16:00:00' and '2021-03-28 16:59:59'
#결과
# 1 kim
# 2 park
# 3 lee여기서 select 절을 "select distinct emp.id, emp.name, access.access.dt"로 변경할 경우 어떤 결과 값이 출력될까요?
이경우 emp.id, emp.name, access.access.dt를 하나의 unique한 행으로 묶기 때문에 다음과 같이 출력됩니다.

3. group by 란
group by는 특정 컬럼을 기준으로 그룹화 하는 명령어입니다.
그룹화를 하면 집계함수를 이용해서 통계데이터(평균, 합계 등)을 구할 수 있습니다.
그룹화 작업을 진행하면서 내부적으로 정렬을 수행합니다. 정렬을 수행하고 싶지 않다면 order by null 을 추가해주면 됩니다.
자세한 내용을 알고 싶다면 아래 링크로 이동해주세요.
2021.03.28 - [IT/Mysql & MariaDB] - [Mysql] group by와 having
4. distinct와 group by의 차이점
distinct와 group by 모두 중복된 데이터를 지울 수 있지만 용도 별로 사용되는 경우가 다릅니다.
distinct는 unique한 행을 조회할 때 사용하고, group by는 집계 데이터를 구할 때 사용합니다.
그래서 distinct와 group by 별로 추출 가능한 데이터가 다릅니다.
특정 시간 사이에 접근한 사원수를 구할 경우 distinct가 유리하고,
사원 별로 특정 시간에 접근한 회수를 구할 경우 group by가 유리합니다.
정확한 이해를 위해서 아래 두 쿼리를 한가지 방식으로만 조회하는 쿼리를 작성해 보시기 바랍니다.
# '2021-03-28 16:00:00' ~ '2021-03-28 16:59:59' 사이에 접근한 사원 수
select count(distinct emp.id)
from employee emp
join access_log access on (access.emp_id = emp.id)
where access.access_dt between '2021-03-28 16:00:00' and '2021-03-28 16:59:59'
# 결과
# 3
# 사원 별로 '2021-03-28 16:00:00' ~ '2021-03-28 16:59:59' 사이에 접근한 회수
select emp.name, count(emp.id)
from employee emp
join access_log access on (access.emp_id = emp.id)
where access.access_dt between '2021-03-28 16:00:00' and '2021-03-28 16:59:59'
group by emp.id
# 결과
# kim 3
# park 1
# lee 3'IT > Mysql & MariaDB' 카테고리의 다른 글
| [Mysql] 데이터 정의어 (DDL) (1) | 2021.04.04 |
|---|---|
| [Mysql] 조인 (JOIN) 이란? (0) | 2021.04.03 |
| [Mysql] group by와 having (1) | 2021.03.28 |
| [Mysql] group by 시 가장 큰 값을 가진 row 조회하기 (0) | 2021.03.27 |
| [Mysql] delete join (0) | 2021.02.25 |