다운받은 Apache-NetBeans-11.3-bin-windows-x64.exe를 실행시키면 Java EE, HTML5/Javascript, PHP 등 여러가지 통합 개발 환경을 지원하는데, 필요한 개발환경만 설치해주시면 됩니다. 특별한 설정 없이 Next 버튼을 누르면 설치가 완료됩니다.
netbeans 11을 실행하면 오른쪽 아래에 에러 툴팁이 노출될 수 있는데, nb-javac-editor 에러일 경우 install을 눌러 nb-javac-editor를 설치해주세요.
JDK 경로 확인
프로젝트 우 클릭 > Properties > Build > compile > Manage Java Platforms > Platform Folder 확인
9. Apache Tomcat 연동
Tools > Servers > Add Server > Apache Tomcat or TomEE > Server Location 입력 (ex : D:\apache\apache-tomcat-8.5.43) > Username과 Password의 Tomcat Manager 정보를 입력한다. > Finish
람다 함수는 함수형 프로그래밍 언어에서 사용되는 개념으로 익명 함수라고도 한다. Java 8 부터 지원되며, 불필요한 코드를 줄이고 가독성을 향상시키는 것을 목적으로 두고있다.
2. 람다 함수의 특징
메소드의 매개변수로 전달될 수 있고, 변수에 저장될 수 있다. 즉, 어떤 전달되는 매개변수에 따라서 행위가 결정될 수 있음을 의미한다.
컴파일러 추론에 의지하고 추론이 가능한 코드는 모두 제거해 코드를 간결하게 한다.
3. 람다식 표현
파라미터와 몸체로 구분된다.
파라미터와 몸체 사이에 -> 구분을 추가하여 람다식을 완성시킨다.
몸체 부분이 단일 행일 경우 중괄호와 return문을 생략할 수 있다.
( 파라미터 ) -> { 몸체 }
4. 익명함수를 람다식으로 변경하기
기존 방법
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Thread!");
}
}).start();
람다식
new Thread(() -> {
System.out.println("Thread!");
}).start();
기존의 방식은 Thread 사용 시 Runnable 인터페이스를 익명함수로 구현하였지만, Java 1.8부터 람다 함수을 통해 구현할 수 있게 되었다.
람다 함수를 매개변수로 넘기기 위해서는 메소드의 매개변수가 @FunctionalInterface로 선언된 인터페이스여야한다. @FunctionalInterface이 선언된 인터페이스를 함수 인터페이스라 불리는데, 조건으로 반드시 추상 메소드 한개만 정의되어 있어야 한다.
그러면 람다식을 매개변수로 저장한 Runnable 인터페이스는 함수형 인터페이스일까?
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface <code>Runnable</code> is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
Runnable 인터페이스를 보면 @FunctionalInterface와 한개의 추상메소드가 선언되어 있다. 즉, 함수형 인터페이스 조건에 성립하는 것이다.
5. 함수형 인터페이스
함수형 인터페이스의 조건
@FunctionalInterface 어노테이션을 선언해야한다.
추상 메소드가 한개만 선언되어야한다.
interface로 선언되어야한다.
이렇게 람다식을 위한 함수형 인터페이스 선언 조건에 대해서 알아보았다. 하지만 Java의 함수형 프로그래밍에는 큰 단점이 있다. 그것은 함수형 인터페이스 안에 선언된 메소드에 종속되는 람다식 밖에 구현할 수 없다는 점이다. 그래서 매개변수의 타입과 개수, 반환 값의 유무 등을 가진 메소드를 하나의 함수형 인터페이스로 구현할 수 없고, 필요한 동작에 따라서 함수형 인터페이스를 만들어줘야한다.
하지만 자바에서 우리가 사용할만한 함수형 인터페이스를 미리 정의해두었다.
Suplier<T>
Consumer<T>
Function<T,R>
Predicate<T>
1). Suplier<T>
매개 변수는 없고, 반환 값이 있는 함수형 인터페이스이다. 추상 메소드 T supplier()를 가진다.
위에 선언된 consumer는 void accept(String s) 메소드를 참조할 수 있다 그리고 System.out.println()는 void println(String str)로 선언된 메소드이다. 그래서 consumer는 println 메소드를 :: 연산자를 통해 참조 가능하다.
퀵 정렬이란 찰스 앤터니 리처드 호어가 개발한 정렬 알고리즘이다. 컴퓨터로 가장 많이 구현된 정렬 알고리즘 중 하나 이고, 평균적인 상황에서 최고의 성능을 낸다.
퀵 정렬의 특징
분할 정복 알고리즘이다.
최악 시간복잡도 O(n²), 평균 시간복잡도 O(n log n)
퀵정렬은 불안정 정렬에 속하며 다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬이다.
퀵 정렬 알고리즘
리스트에서 적절한 피벗(원소) 하나를 고르고, 피벗 앞에는 피벗보다 작은 값들이 오게 하고, 피벗 뒤에는 피벗보다 큰 값들이 오게 한다. 작업이 완료되면 피벗을 기준으로 두 개의 리스트가 생기는데, 각각 리스트에도 이전에 했던 과정을 재귀적으로 반복해준다. 리스트가 더 이상 나누어지지 않는다면, 재귀반환하면서 여러 개의 정렬된 리스트를 하나의 리스트로 결합해준다.
safe_to_bootstrap 값이 1인 경우 마지막으로 죽은 노드를 의미하기 때문에 해당 기준 노드로 실행합니다.
galera_new_cluster
실행이 완료 되면 나머지 노드도 실행해줍니다.
systemctl start mariadb
여기까지 완료되었다면 모든 노드에서 MariaDB 로그인 후 연결된 노드 개수가 맞는지 확인합니다.
> show global status like 'wsrep_cluster_size';
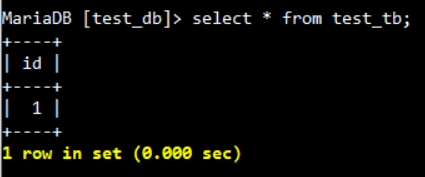
각 노드에서 위 명령어 입력 시, 예상했던 노드 개수와 일치하지 않다면, 해당 노드는 동기화 상태가 아닐 확률이 높습니다. 이때, 사용하고 있는 DB의 테이블을 SELECT 해봅니다.
WSREP has not yet prepared node for application use
위와 같은 오류가 발생하면 동기화 상태가 아니므로 WSREP의 pc.bootstrap 옵션을 YES로 바꾸어주어야 합니다.
> SET GLOBAL wsrep_provider_options='pc.bootstrap=YES'; Query OK, 0 rows affected (0.000 sec)
위 옵션을 적용하고 나서 MariaDB를 옵션을 적용한 노드를 재시작해주어야 합니다. 재시작 후에 test_tb가 잘 조회되는지 확인해주고 show global status like 'wsrep_cluster_size'; 명령어를 입력하여 클러스터 사이즈가 3인지 확인해줍니다.
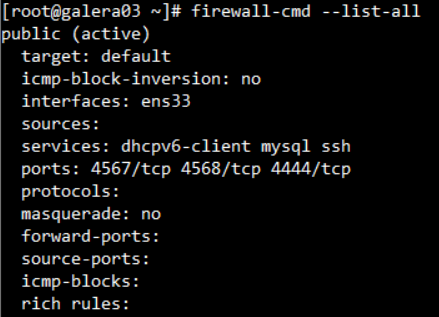
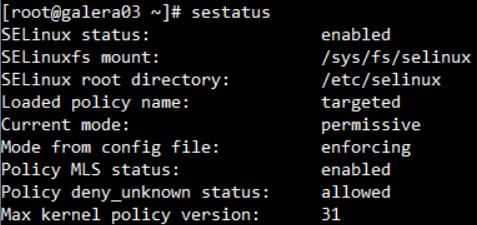
모든 복구가 완료되면 setenforce 1 명령어를 실행해줍니다.
8. gelera Cluster Test
테스트 환경
HostName
galera03
galera04
galera05
IP Address
192.168.152.143
192.168.152.144
192.168.152.145
OS
CentOS 7
CentOS 7
CentOS 7
MariaDB Version
MariaDB 10.4
MariaDB 10.4
MariaDB 10.4
테스트 설명
Case 1 로그 데이터 10만건 삽입 테스트
Case 2 새로운 노드 추가 및 동기화 테스트
Case 1 - 로그 데이터 10만건 삽입 테스트
테스트 방법
Java에서 Galera Cluster로 이중화된 galera03, galera04을 JDBC를 이용해 연결한다.